找不到 config.guess 和 config.sub 文件
现象:
configure: error: cannot find required auxiliary files: config.guess config.sub
解决办法:
automake --add-missing
PPM格式说明
PPM 是一种很方便的图片文件格式,它的结构为:
PPM类型标识
图像宽度 图像高度 颜色的最大值
R G B R G B R G B R G B R G B R G B ...
| PPM类型标识 | 图像类型 | 数据表示方式 |
|---|---|---|
| P1 | 二值图像 | 文本格式 |
| P2 | 灰度图像 | 文本格式 |
| P3 | 彩色图像 | 文本格式 |
| P4 | 二值图像 | 二进制格式 |
| P5 | 灰度图像 | 二进制格式 |
| P6 | 彩色图像 | 二进制格式 |
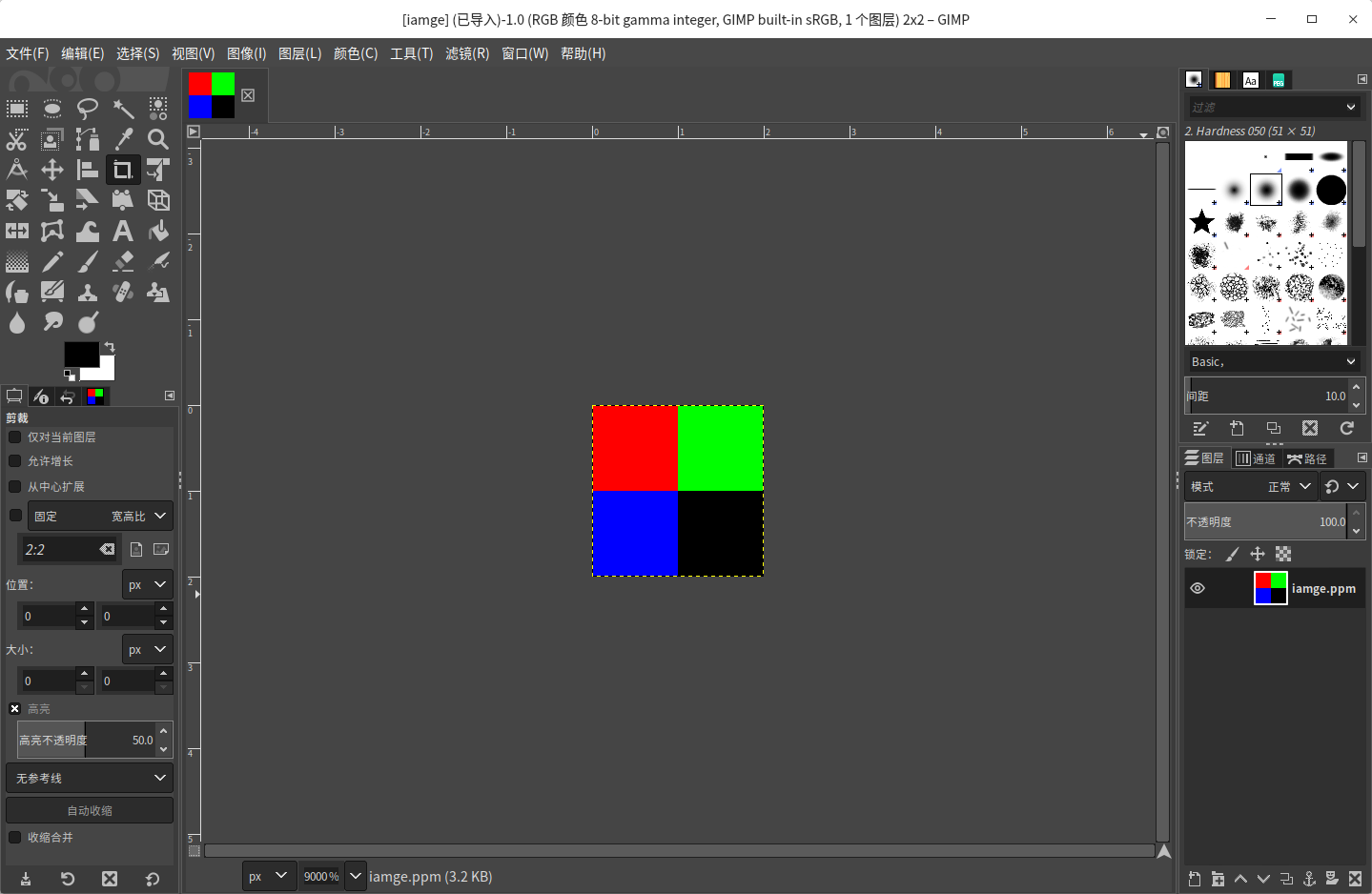
例如一个下面这张图
P3
2 2 255
255 0 0 0 255 0
0 0 255 0 0 0
VS Code 下载慢的解决办法
将下载链接的域名改为 vscode.cdn.azure.cn,这是微软在国内的 CDN 地址。
例如 https://az764295.vo.msecnd.net/stable/899d46d82c4c95423fb7e10e68eba52050e30ba3/code_1.63.2-1639562499_amd64.deb
改为 https://vscode.cdn.azure.cn/stable/899d46d82c4c95423fb7e10e68eba52050e30ba3/code_1.63.2-1639562499_amd64.deb
可以使用下面的 Python 脚本进行下载:
$ python vscode-download.py --os linux-deb-x64
Request https://code.visualstudio.com/sha/download?build=stable&os=linux-deb-x64
Redirect to https://az764295.vo.msecnd.net/stable/704ed70d4fd1c6bd6342c436f1ede30d1cff4710/code_1.77.3-1681292746_amd64.deb
Redirect to https://vscode.cdn.azure.cn/stable/704ed70d4fd1c6bd6342c436f1ede30d1cff4710/code_1.77.3-1681292746_amd64.deb
Download 88538392/88538392 bytes
Done.
#! /usr/bin/env python3
# author: planc
# e-mail: hubenchang0515@outlook.com
# repo: https://github.com/hubenchang0515/Moe-Maid/blob/master/vscode-download.py
import argparse
import urllib.request
import urllib.parse
from pathlib import Path
os_options: list[str] = [
"win32-x64-user",
"win32-user",
"win32-arm64-user",
"win32-x64",
"win32",
"win32-arm64",
"win32-x64-archive",
"win32-archive",
"win32-arm64-archive",
"cli-win32-x64",
"cli-x64",
"cli-arm64-x64",
"linux-deb-x64",
"linux-deb-armhf",
"linux-deb-arm64",
"linux-rpm-x64",
"linux-rpm-armhf",
"linux-rpm-arm64",
"linux-x64",
"linux-armhf",
"linux-arm64",
"cli-alpine-x64",
"cli-alpine-armhf",
"cli-alpine-arm64",
"darwin",
"darwin-arm64",
"darwin-universal",
"cli-darwin-x64",
"cli-darwin-arm64",
]
build_options: list[str] = [
"stable",
"insider"
]
class RedirectHandler(urllib.request.HTTPRedirectHandler):
def __init__(self, cdn) -> None:
super().__init__()
self.__cdn = cdn
def redirect_request(self, req, fp, code, msg, headers, newurl):
print(f"Redirect to {newurl}")
parts = urllib.parse.urlparse(newurl)
parts = parts._replace(netloc=self.__cdn)
newurl = parts.geturl()
print(f"Redirect to {newurl}")
return urllib.request.Request(newurl)
if __name__ == "__main__":
build_options:str = "\n\t".join(build_options)
os_options:str = "\n\t".join(os_options)
parser = argparse.ArgumentParser(description="Download VS Code with CDN",
epilog=f"build options:\n\t{build_options}\n\nos options:\n\t{os_options}\n",
formatter_class=argparse.RawTextHelpFormatter)
parser.add_argument("--os", required=True, help="operating system")
parser.add_argument("--build", required=False, help="build type, default 'stable'", default="stable")
parser.add_argument("--cdn", required=False, help="CDN url, default 'vscode.cdn.azure.cn'", default="vscode.cdn.azure.cn")
parser.add_argument("--proxy", required=False, help="proxy, default None")
args = parser.parse_args()
if args.proxy is None:
proxies = None
else:
proxies = {
"http": args.proxy,
"https": args.proxy,
"socks5": args.proxy,
}
proxy_handler = urllib.request.ProxyHandler(proxies=proxies)
redirect_handler = RedirectHandler(args.cdn)
opener = urllib.request.build_opener(proxy_handler, redirect_handler)
params = urllib.parse.urlencode({'build': args.build, 'os': args.os})
url:str = f"https://code.visualstudio.com/sha/download?{params}"
print(f"Request {url}")
with opener.open(url) as response:
parts = urllib.parse.urlparse(response.geturl())
path = Path(parts.path)
total_bytes:int = int(response.getheader('Content-Length'))
done_bytes:int = 0
with open(path.name, mode="wb") as fp:
while done_bytes < total_bytes:
data = response.read(4*1024)
if data is None:
break
fp.write(data)
done_bytes += len(data)
print(f"Download {done_bytes}/{total_bytes} bytes", end="\r")
print("\nDone.")
idx-ubyte 文件格式
idx-ubyte 是一种很简单的二进制文件格式,著名的 MNIST 使用的就是该格式。
它由一个 magic-number 和各个维度的长度组成 header,然后是主体数据。magic-number 和维度的长度都是 32 位大端无符号整数。
- idx1-ubyte 的数据有一个维度,magic-number 的值为 0x00000801
- idx3-ubyte 的数据有三个维度,magic-number 的值为 0x00000803
struct Idx1Ubyte
{
uint32_t magicNumber;
uint32_t dim1;
uint8_t datas[];
};
struct Idx3Ubyte
{
uint32_t magicNumber;
uint32_t dim1;
uint32_t dim2;
uint32_t dim3;
uint8_t datas[];
};
以 MNIST 为例 :
- train-images.idx3-ubyte 是训练集图片
- 维度 1 的值是 6000,表示包含 6000 张图片
- 维度 2 的值是 28,表示一张图片有 28 行像素
- 维度 3 的值是 28,表示一张图片有 28 列像素
- train-labels.idx1-ubyte 时训练集标注
- 维度 1 的值是 6000,表示包含 6000 个标注
#ifndef IDX_UBYTE_HPP
#define IDX_UBYTE_HPP
#include <cstdio>
#include <cstdint>
#include <cstring>
#include <cerrno>
#include <vector>
template<uint8_t N>
struct IdxUbyteData
{
uint8_t* data = nullptr;
uint32_t dims[N];
IdxUbyteData() noexcept = default;
~IdxUbyteData() noexcept
{
if (data != nullptr)
{
delete[] data;
data = nullptr;
}
}
IdxUbyteData(IdxUbyteData&& src) noexcept
{
data = src.data;
src.data = nullptr;
memcpy(dims, src.dims, sizeof(dims));
}
IdxUbyteData(const IdxUbyteData& src) noexcept
{
memcpy(dims, src.dims, sizeof(dims));
size_t bytes = 1;
for (uint32_t i = 0; i < N; i++)
{
bytes *= dims[i];
}
data = new uint8_t[bytes];
memcpy(data, src.data, bytes);
}
};
template<uint8_t N>
class IdxUbyte
{
public:
IdxUbyte() noexcept = default;
~IdxUbyte() noexcept = default;
bool write(const char* file, const std::vector< IdxUbyteData<N-1> >& dataset) const noexcept
{
if (dataset.size() == 0)
return false;
FILE* fp = fopen(file, "wb");
if (fp == nullptr)
{
fprintf(stderr, "%s\n", strerror(errno));
return false;
}
this->m_write<32>(fp, MagicNumber);
this->m_write<32>(fp, dataset.size());
size_t bytes = 1;
for (uint32_t i = 0; i < N-1; i++)
{
this->m_write<32>(fp, dataset[0].dims[i]);
bytes *= dataset[0].dims[i];
}
for (const auto& data : dataset)
{
if (fwrite(data.data, 1, bytes, fp) < bytes)
{
fprintf(stderr, "%s\n", strerror(errno));
}
}
fclose(fp);
return true;
}
std::vector< IdxUbyteData<N-1> > read(const char* file) const noexcept
{
std::vector< IdxUbyteData<N-1> > ret(0);
FILE* fp = fopen(file, "rb");
if (fp == nullptr)
{
fprintf(stderr, "%s\n", strerror(errno));
return ret;
}
uint32_t magic = this->m_read<32>(fp);
if (magic != MagicNumber)
{
fprintf(stderr, "magic number mismatch: 0x%08x != 0x%08x\n", magic, MagicNumber);
fclose(fp);
return ret;
}
uint32_t dims[N];
for (size_t i = 0; i < N; i++)
{
dims[i] = this->m_read<32>(fp);
printf("dim %zu: %u\n", i, dims[i]);
}
for (uint32_t i = 0; i < dims[0]; i++)
{
size_t bytes = 1;
IdxUbyteData<N-1>& data = ret.emplace_back();
for (size_t j = 1; j < N; j++)
{
data.dims[j-1] = dims[j];
bytes *= dims[j];
}
data.data = new uint8_t[bytes];
if (fread(data.data, 1, bytes, fp) < bytes)
{
fprintf(stderr, "%s\n", strerror(errno));
}
}
fclose(fp);
return ret;
}
private:
constexpr static const uint32_t MagicNumber = 0x00000800 | N;
// 大端读
template<size_t bits>
uint32_t m_read(FILE* fp) const noexcept
{
uint32_t ret = 0;
uint8_t byte = 0;
for (size_t i = 0; i < bits / 8; i++)
{
ret <<= 8;
if (fread(&byte, 1, 1, fp) < 1)
{
fprintf(stderr, "%s\n", strerror(errno));
}
ret |= byte;
}
return ret;
}
// 大端写
template<size_t bits>
void m_write(FILE* fp, uintmax_t value) const noexcept
{
constexpr const size_t bytes = bits / 8;
uint8_t byte = 0;
for (size_t i = 1; i <= bytes; i++)
{
byte = static_cast<uint8_t>(value >> (8 * (bytes - i)));
fwrite(&byte, 1, 1, fp);
}
}
};
#endif // IDX_UBYTE_HPP
一些常见的延迟级别
亚纳秒级
- CPU 访问寄存器
- CPU 时钟周期
纳秒级
- 访问 L1/L2 缓存
- 分支预测错误惩罚
十纳秒级
- 访问 L3 缓存
百纳秒级
- 系统调用(仅调用本身的开销,不包含执行过程的开销)
- 计算 64 位数字的 MD5 值
微秒级
- 线程上下文切换(仅切换本身的开销,不包含切换可能引发的内存换页等开销)
- 64KB 内存页拷贝
十微秒级
- Nginx 处理一个 HTTP 请求
- SSD 读取一个 8KB 页
百微秒级
- SSD 写入一个 8KB 页
- 云服务域内网络往返
- 一次 Redis 读取
毫秒级
- 云服务域间网络往返
- 机械硬盘寻道
十毫秒级
- 美国西海岸到东海岸的网络延迟
- 内存顺序读取 1GB
百毫秒级
- bcrypt 加密一个常规长度的密码
- TLS 握手
- 中国到美国的网络延迟
- SSD 顺序读取 1GB
秒级
- 云服务域内传输 1GB 数据
数字高程模型数据下载
SRTM
下载地址: https://srtm.csi.cgiar.org/srtmdata/
Mars MGS MOLA DEM 463m v2
Mars MGS MOLA DEM 463m v2 是 NASA 发布的火星数字高程模型数据。
ETOPO(1.8千米)
ETOPO是一种地形高程数据,由NGDC美国地球物理中心发布,与大多数高程数据不同的是,它还包含海底地形数据。
下载地址: https://www.ncei.noaa.gov/products/etopo-global-relief-model
SRTM15(450米)
SRTM15的空间分辨率为 15 弧秒,精度相当于 0.5km左右,包含了陆地高程和海洋深度数据。
下载地址: https://topex.ucsd.edu/WWW_html/srtm15_plus.html
GMTED(250米)
来自美国地质勘探局USGS和美国国家地理空间情报局NGA,它是对USGS的GTOPO30的进一步优化和发展,对应的最高精度在250米左右。
下载地址: https://www.usgs.gov/coastal-changes-and-impacts/gmted2010
SRTM3(90米)
SRTM,全称为Shuttle Radar Topography Mission,该项目获取了北纬60度至南纬60度之间的雷达影像数据,SRTM3,即精度为3弧秒,即90m一个点,包括非洲、北美、南美、欧亚、澳大利亚以及部分岛屿。
下载地址: http://www.webgis.com/srtm3.html
ASTER GDEM(30米)
全称Advanced Spaceborne Thermal Emission and Reflection Radiometer Global Digital Elevation Model ,即先进星载热发射和反射辐射仪全球数字高程模型,其数据覆盖范围为北纬83°到南纬83°之间的所有陆地区域,达到了地球陆地表面的99%,所以应用十分的广泛。目前比较常用的是 ASTER GDEM V2,另外ASTER GDEM V3也比较常见,质量比V2版本要好的多。
ALOS(12.5米)
ALOS DEM是ALOS(Advanced Land Observing Satellite卫星相控阵型L波段合成孔径雷达(PALSAR)采集,该数据水平及垂直精度可达12.5米。
软件激活功能的实现方法
常用激活方式
完全离线激活
通过某种算法规则生成激活码,软件通过该规则对激活码进行验证。用户只要将激活码填入软件即可。
规则示例:
- 激活码由四个两数组成
AA-BB-CC-DD - 规则为
DD = (AA + BB + CC) % 100
这种方法使用起来最方便,但安全性极差,一个激活码即可无限激活。
部分离线激活
设备本身离线,但激活时需要其他联网设备复制进行,激活后使用软件不需要联网。
步骤:
- 软件获取设备 ID
- 用户通过其他联网环境再注册网页上提交设备 ID
- 注册服务器根据设备ID,以某种算法规则生成注册码返回给用户
- 用户在软件上填入该激活码激活
- 软件以该规则进行验证
规则示例:
- 激活码 = SHA256(设备ID)
这种方法使用起来也较为方便,且一个激活码只能用于一台设备。但也有算法被破解的风险。
在线激活
设备全程联网验证。这种方式最安全,但对用户而言十分麻烦。
获取唯一设备 ID
X86 汇编中有一条
cpuid指令,可以获取 CPU 的 ID,原本包含 CPU 的序列号,但出于隐私保护的原因被取消了,现在 CPU ID 仅含 CPU 型号,而不包含序列号。
可以采用 硬盘序列号 作为设备ID,获取方法如下:
Linux 上获取硬盘序列号
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#include <linux/limits.h>
#include <libmount/libmount.h>
#include <libudev.h>
#define SERIAL_MAX_LENGTH 1024
// 通过 libmount 获取挂载点的硬盘设备路径
const char* device_path_of_mount_point(const char* mount_point)
{
static char device_path[PATH_MAX];
device_path[0] = 0;
struct libmnt_context* ctx = mnt_new_context();
if (ctx == NULL)
return NULL;
struct libmnt_table* table = NULL;
if (mnt_context_get_fstab(ctx, &table) < 0)
{
mnt_free_context(ctx);
return NULL;
}
struct libmnt_fs* fs = mnt_table_find_target(table, mount_point, MNT_ITER_BACKWARD);
if (fs == NULL)
{
mnt_free_context(ctx);
return NULL;
}
const char* path = mnt_fs_get_srcpath(fs);
strncpy(device_path, path, PATH_MAX);
mnt_free_context(ctx);
return device_path;
}
// 通过 libudev 获取设备路径的序列号
const char* serial_of_device(const char* device_path)
{
static char device_serial[SERIAL_MAX_LENGTH];
device_serial[0] = 0;
struct udev* udev = udev_new();
if (udev == NULL)
return NULL;
struct udev_enumerate* enumerate = udev_enumerate_new(udev);
if (enumerate == NULL)
{
udev_unref(udev);
return NULL;
}
if (udev_enumerate_scan_devices(enumerate) < 0)
{
udev_enumerate_unref(enumerate);
udev_unref(udev);
return NULL;
}
struct udev_list_entry* device_entry = udev_enumerate_get_list_entry(enumerate);
udev_list_entry_foreach(device_entry, device_entry)
{
const char* syspath = udev_list_entry_get_name(device_entry);
struct udev_device* device = udev_device_new_from_syspath(udev, syspath);
struct udev_list_entry* link_entry = udev_device_get_devlinks_list_entry(device);
udev_list_entry_foreach(link_entry, link_entry)
{
const char* link = udev_list_entry_get_name(link_entry);
if (strcmp(link, device_path) == 0)
{
const char* serial = udev_device_get_property_value(device, "ID_SERIAL");
strncpy(device_serial, serial, SERIAL_MAX_LENGTH);
udev_device_unref(device);
goto SUCCESS;
}
}
udev_device_unref(device);
}
SUCCESS:
udev_enumerate_unref(enumerate);
udev_unref(udev);
return device_serial;
}
int main (int argc, char *argv[])
{
const char* device_path = device_path_of_mount_point("/");
if (device_path == NULL)
return EXIT_FAILURE;
const char* device_serial = serial_of_device(device_path);
printf("Path: %s \nSerial: %s\n", device_path, device_serial);
return EXIT_SUCCESS;
}
Windows 上获取硬盘序列号
#include <Windows.h>
#include <stdio.h>
#include <stdlib.h>
#define SERIAL_MAX_LENGTH 1024
const char* serial_of_device(const char* device_path)
{
static char device_serial[SERIAL_MAX_LENGTH];
device_serial[0] = 0;
HANDLE device = CreateFileA(device_path, 0, 0, NULL, OPEN_EXISTING, 0, NULL);
if (device == INVALID_HANDLE_VALUE)
return NULL;
STORAGE_PROPERTY_QUERY query;
query.PropertyId = StorageDeviceProperty;
query.QueryType = PropertyStandardQuery;
// 查询存储器头
STORAGE_DESCRIPTOR_HEADER header;
BOOL success = DeviceIoControl(device, IOCTL_STORAGE_QUERY_PROPERTY, &query, sizeof(query), &header, sizeof(header), NULL, NULL);
if (!success || header.Size == 0)
{
CloseHandle(device);
return NULL;
}
// 查询存储器全部属性
void* buffer = malloc(header.Size);
if (buffer == NULL)
{
CloseHandle(device);
return NULL;
}
success = DeviceIoControl(device, IOCTL_STORAGE_QUERY_PROPERTY, &query, sizeof(query), buffer, header.Size, NULL, NULL);
if (!success)
{
free(buffer);
CloseHandle(device);
return NULL;
}
// 获取序列号的偏移并读取序列号
const STORAGE_DEVICE_DESCRIPTOR* descriptor = (STORAGE_DEVICE_DESCRIPTOR*)buffer;
strncpy(device_serial, (char*)buffer + descriptor->SerialNumberOffset, SERIAL_MAX_LENGTH);
free(buffer);
CloseHandle(device);
return device_serial;
}
int main()
{
const char* device_serial = serial_of_device("\\\\.\\C:");
if (device_serial == NULL)
return EXIT_FAILURE;
printf("%s\n", device_serial);
return EXIT_SUCCESS;
}
Phosphophyllite
SEO 友好的纯静态 Markdown 博客系统
SEO-friendly pure static Markdown blog system
Usage - 使用说明
存储结构:
blog/article用于存储文章blog/resource用户存储资源文件,例如图片
Storage Structure:
blog/articleis used to store articlesblog/resourceis used to store resource files such as images
Build & Deploy - 构建与部署
python main.py